Smyrna
An easy Polish concordancer in Clojure
Daniel Janus
@nathell
What is a concordancer?
What is a concordance?

Corpus
A body of searchable text
KWIC
Keywords in Context
Sample concordance: sin
| said cohabiting was no longer a | sin | . Serbs free last six |
| daily care of others was the ultimate | sin | . We arranged for Ted to spend a |
| remarkable. Shaw’s rendition was a | sin | against culture, an insult to Eliot |
| them that God wants them to turn from | sin | and transform their lives. Women |
| the ascendancy to and loss of power; | sin | and redemption; self-doubt and |
Source: ICT4LT
Poliqarp
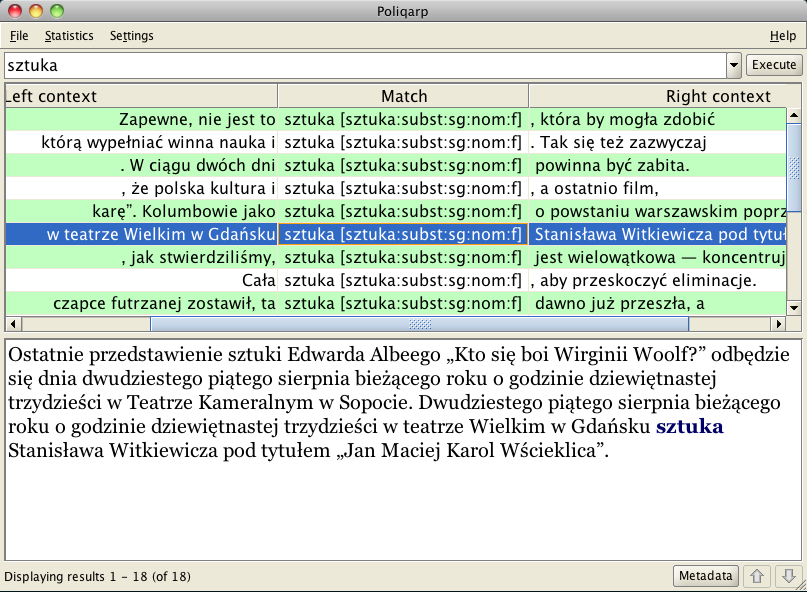
Poliqarp (2004)
- IPI PAN Corpus & National Corpus of Polish
- Supports large corpora (~1G words)
- Supports Polish inflection
- Versatile query language
- Very hard to use with custom corpora
Smyrna: a simple utility
- Corpus creation: a few clicks
- Query: just type a word
- KWIC reinvented: just press left/right
- Frequency list: just press a button
- Still supports Polish inflection
- Less than 500 lines of code
Demo
Desktop meets browser
- Backend: Clojure (~ 240 LOC)
- GUI: CoffeeScript (~ 240 LOC)
- Both typically run on the same machine
- Communication: JSON-RPC (clj-json-rpc)
State
(def state (atom {}))Map from corpora names to lists of files and indexes, wrapped in an atom
Accessing state
(defn-json-rpc frequency-list [corpus]
(sort-by second >
(into []
(map vec
(-> @state
(get corpus)
:index
:lemma-global-frequency)))))Updating state
(slightly simplified for clarity)
(defn-json-rpc add-corpus [name directory]
(let [files (filter (comp #{"html" "htm" "HTML" "HTM"}
extension)
(file-seq (file directory)))]
(do
(swap! state assoc name
{:directory directory
:num-files (count files)
:index (core/index-fileset files)})
(future (write-to config-file @state))
true)))Current work
- True tagging
- Document metadata
Why tag?
- We want to count and query lexemes, not individual word forms
- Currently used: morphological dictionary (Morfologik)
- Problem: ambiguity
ale “but”
120 ala “ancient Roman cavalry”
120
Tagging
=
morphological analysis
+
context-based disambiguation
English is easy
play
plays
played
playing
Polish is not quite so easy
| gra | gracie | graj | grajcie | grajcież | grajmy | grajmyż |
| grają | grając | grająca | grające | grającego | grającej | grającemu |
| grający | grających | grającym | grającymi | grającą | grajże | grali |
| graliby | gralibyście | gralibyśmy | graliście | graliśmy | gram | gramy |
| grana | grane | granego | granej | granemu | grani | grania |
| graniach | graniami | granie | graniem | graniom | graniu | grano |
| grany | granych | granym | granymi | graną | grasz | grał |
| grała | grałaby | grałabym | grałabyś | grałam | grałaś | grałby |
| grałbym | grałbyś | grałem | grałeś | grało | grałoby | grały |
| grałyby | grałybyście | grałybyśmy | grałyście | grałyśmy | grań | niegrająca |
| niegrające | niegrającego | niegrającej | niegrającemu | niegrający | niegrających | niegrającym |
| niegrającymi | niegrającą | niegrana | niegrane | niegranego | niegranej | niegranemu |
| niegrani | niegrania | niegraniach | niegraniami | niegranie | niegraniem | niegraniom |
| niegraniu | niegrany | niegranych | niegranym | niegranymi | niegraną | niegrań |
Polish is hard
Over 3000 theoretically possible grammatical word descriptions,
over 1000 occurring in the wild
Positional tagsets
subst:sg:acc:m1
| subst | part of speech | noun |
| sg | number | singular |
| acc | case | accusative |
| m3 | gender | masculine inanimate |
How to tag?
- Statistical methods, trained automatically
- Rule-based, with manually created rules
- Rule-based, with automatically inferred rules
Brill tagging
- Start with most frequent tags for each word
- Generate a list of plausible rules
- While it improves the quality of tagging:
- Pick a rule that makes the best improvement
- Add it to the set of rules and apply
More information: S. Acedański, A Morphosyntactic Brill Tagger for Inflectional Languages, in Advances in Natural Language Processing, 2010, pp. 3-14
Implementation
- Rule inference: PANTERA
(a Brill tagger written in C++) - Rule application: clj-nkjp
(a library in pure Clojure)
A sample PANTERA rule
((T[1]|pos,case = *,inst OR
T[2]|pos,case = *,inst OR
T[3]|pos,case = *,inst) AND
T[0]|pos,case = prep,gen) -> T[0]|case := instHow do we make this rule understandable by Clojure?
Instaparse!
(def grammar
"S = COND ' -> ' ACTION
COND = SIMPLECOND | '(' COND ')' | COND ' OR ' COND | COND ' AND ' COND
SIMPLECOND = TAGPART ' = ' VALSPEC | SEGSPEC ENDSWITH WORDSPEC | SEGSPEC STARTSWITH WORDSPEC
WORDSPEC = '\\'' WORD '\\'' | 'capital letter'
SEGSPEC = TAG | 'nearby segment' | 'ORTH' | 'ORTH[' NUMBER ']'
TAG = 'T[' NUMBER ']'
TAGPART = TAG | TAG '|' TAGSPEC
ENDSWITH = ' ends ' ('(' NUMBER ' chars) ')? 'with '
STARTSWITH = ' starts with '
NUMBER = #'-?[0-9]+'
TAGSPEC = #'[a-z,]+'
VALSPEC = #'[a-z0-9,*:]+'
WORD = #'[-ąćęłńóśźża-z,.]+'
ACTION = TAGPART ' := ' VALSPEC")From AST to code (1)
(error checking omitted for clarity)
(defn rule-code
[{:keys [condition action], :as rule}]
`(fn [text# pos#]
(let [~'tag (fn [i#] (vget text# (+ i# pos#)))
~'current-seg (~'tag 0)]
(if ~(compile-condition condition)
~(compile-action action)
~'current-seg))))From AST to code (2)
(shortened for clarity)
(defn compile-condition [cnd]
(condp = (first cnd)
;; ... other conditions ...
:= (cond
(= (descend cnd 1 0) :tag)
(let [parsed-tag (tagset/parse-ctag (nth cnd 2))]
`(= (select-keys (~'tag ~(descend cnd 1 1))
~(vec (keys parsed-tag))) ~parsed-tag)))))Just compile it!
(defn compile-rule
[rule]
(eval (rule-code rule)))Questions?
Dziękuję | za | uwagę | ! |
| thank-I.singular.present | for | attention.singular.accusative | ! |
| dziękować:verb:fin:sg | za:qub | uwaga:subst:sg:acc | !:interp |
Daniel Janus